Bringing Van Gogh's Paintings to Life with AI
Explore how I utilized AI Diffusion models to bring Van Gogh's paintings to life in this blogpost.

I posted this video on my YouTube channel, and it received more views than my typical clips. The inspiration for this video came from the works of the renowned Dutch painter Vincent Van Gogh. In the video, I bring motion and life into his paintings using AI. You can watch the clip below.
Alright, when I mentioned that it was generated by AI, it wasn't entirely accurate. The audio was sourced from the NCS channel, and I utilized kdenlive, another excellent open-source software for advanced video editing, to handle the editing of clips, audio, and text. Nevertheless, I wanted to highlight the capability of some the advancements in AI that can be leveraged to create creative content with ease.
Stable Diffusion Art Generation with Web UI#
Before jumping directly into video animation, let us start with the basics, i.e., Image Generation. Image generation has advanced since the introduction of Diffusion models. These are currently the true state-of-the-art (SOTA) models for image generation tasks. If you have a decent GPU with over 4GB VRAM, then you can easily run these models on your system.
To begin, I will use web-ui by AUTOMATIC111, a beginner-friendly UI offering numerous advanced options for executing image generation tasks with Diffusion models.
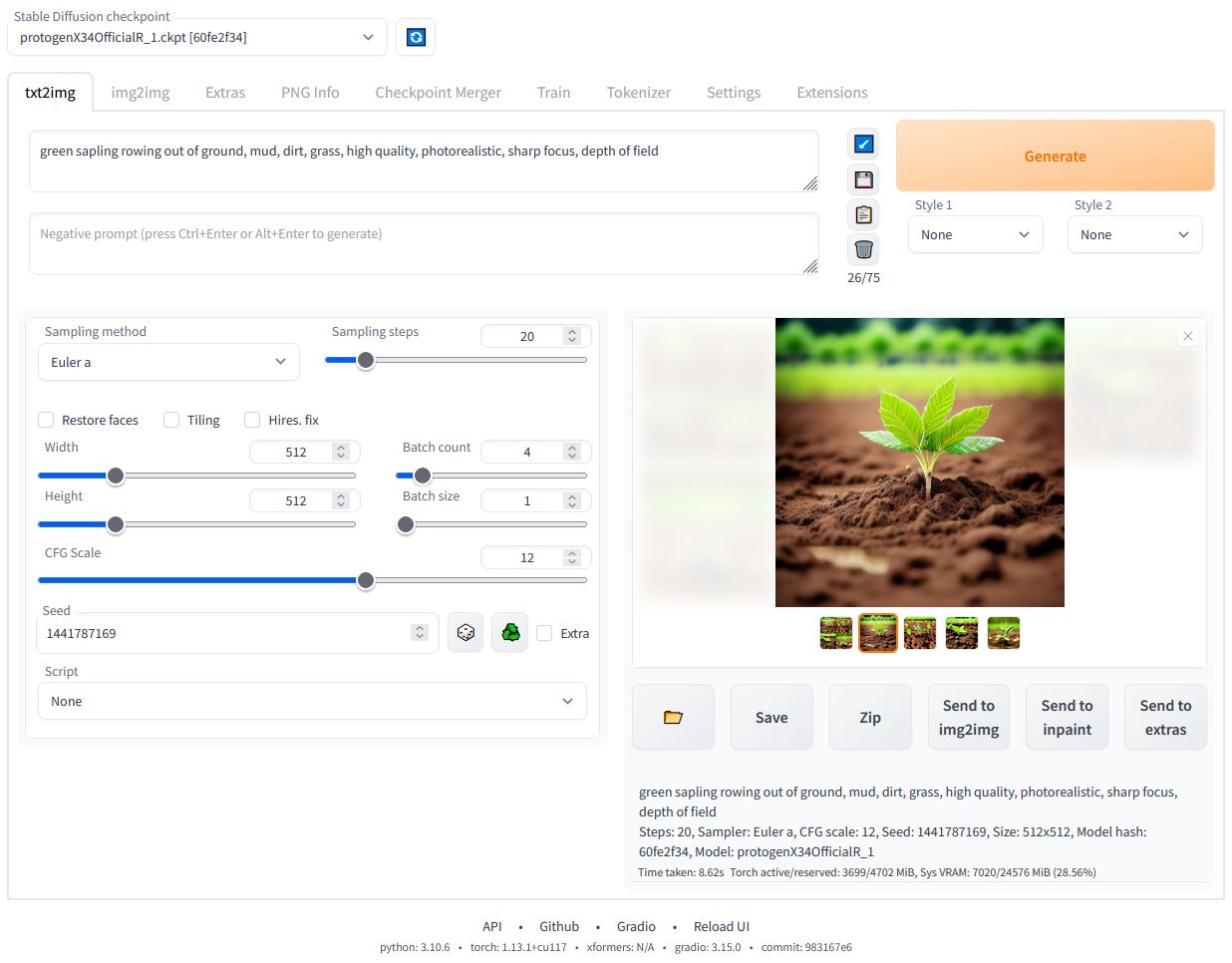
You can follow the instructions to setup the repository in your local machine.
Download one of the model checkpoints and save it in the repository under the models/Stable-diffusion/ location. Refresh the Web UI checkpoint list to find your saved model and select it to load the model into GPU memory.
| Model |
Size (GB) | Link |
|---|---|---|
| Stable Diffusion v1.5 | 2.13 | https://huggingface.co/fp16-guy/Stable-Diffusion-v1-5_fp16_cleaned/blob/main/sd_1.5.safetensors |
| SD Turbo | 5.21 | https://huggingface.co/stabilityai/sd-turbo/blob/main/sd_turbo.safetensors |
| SDXL Turbo | 6.94 | https://huggingface.co/stabilityai/sdxl-turbo/blob/main/sd_xl_turbo_1.0_fp16.safetensors |
| SD v2.1 | 5.21 | https://huggingface.co/stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.safetensors |
Web UI Basics#

We will not go over all the features of the Web UI application (that is for another blog post), but I'll cover some of the basics that will give you an idea of how to get started.
Checkpoint: This is where you can choose the base diffusion model.
Positive Prompt: This text field is where you will type in the prompt that will be used to generate the image. You'd want to describe the image in terms of quality, content, and all other positive factors that you want to see in the image. In my example, I've chosen a simple prompt to create a masterpiece painting of sunflowers in the style of the painter Vincent Van Gogh.
masterpiece, best quality, sunflowers, painting, art by Vincent Van Gogh,Negative Prompt: This is another text field where you can prompt the model on what it should NOT generate. This is good way to guide model to avoid generating bad quality images or to avoid generating a specific subject. In my example, I've showm some basic negative prompt that is most oftenly used to avoid bad image quality.
bad prompt, bad quality, worst quality,Sampling Method: Diffusion model generate the final image by going through intermediate steps where it tries to generate a random image in the latent space and by iteratively predicting and removing the noise from this image. The complete denoising process is termed as Sampling and the Sampling Method refers to the process that guides in selecting the random image. There is no best or worst in sampling methods. With lots of trials and experiments you'd need to find the right one for your use-case.
Here are some random sampling methods and its generations.

Sampling Steps: In Diffusion models, you'd typically need to define how much steps the model has to take for denoising and refinement. This is called as Sampling Steps. The less number of steps, the faster will be your generation but again there is a little trade-off with the image quality. There are latest techniques like LCM or using specific sampling methods like UniPC that will allow you to generate a decent looking image with less number of time-steps.
Hires Fix: This is used to scale-up your output to larger resolution using UpScalar models. Generating larger images require large VRAM, so these Hires fix will come in handy where you can generate a smaller resolution image (e.g 512x512) then using an Upscalaer method you can increase it.
Output Resolution: This is the base resolution to which the diffusion model will generate the initial output. Increasing the resolution will put more load on your GPU. Always use Hires Fix to upscale your images.
CFG Scale: Stands for Classifier-free Guidance, is a parameter to control how much should the model follow the Text Prompts. In another words, you can say that it controls the creativity of the model. Lower CFG means, the model is more flexible to follow what it thinks is right and higher score puts a weight on it to follow the text prompt. This value also depends on your sampling method as some of the methods like UniPC/LCM does not require a large CFG score to generate output.
Generate: You can select this option to start the image diffusion process. The model will use your selected configuration to generate the output. You can also set a predifined Seed to control the randomness in the output generation.
Preview: Finally the resultant image will be available for preview in this section. It also gets stored under the
outputdirectory.
As per the above configuration shown in the previous image, the final image generation for the Van Gogh's sunflower painting looks something like this below.
Output Demo 1#

The image resembles Van Gogh's painting style and also it was able to capture the yellow tints from his sunflower painting.
Animating frames with AnimateDiff#
This paper introduced very first kind of text-to-video prompting using Stable Diffusion. They prosed a framework that leveraged these motion models to animate frames from existing diffusion model output thus generating video. At the time of writing this blog, there is a new and more enhanced text-to-video models called Stable Video Diffusion which is from the same developers as Stable Diffusion. You can check them out as well. But for the purpose of this blogpost, I'll be covering on how to generate video frames using AnimateDiff.
Here is a sample of AnimateDiff.
Setup - AnimateDiff Extension#
Another factor contributing to the popularity of Web UI project is their extension support. Within the Open Source community, a plethora of plugins and extension support exists that adds advanced capabilities. One such extension that integrates AnimeDiff into Web UI is sd-webui-animatediff. To incorporate this extension into your local Web UI setup, follow this guide. Download the required motion modules from the provided links, and you'll be ready to start using it.
Usage - Generating Video#
Navigate to the AnimateDiff configuration window, where you have the option to choose the Frames Per Second (FPS), total number of frames, and looping preferences for the animation frames. Additionally, you can specify the format for saving the video.

Once you have chosen the necessary configuration and motion models, proceed to generate the video using your initial text prompt. It's important to note that the output generation time will be longer compared to image generation. This is expected due to the higher number of frames (images) involved in the generation process and the need to maintain contextual coherence across these frames.
Output Demo 2#

This is how you can animate still images using AnimateDiff. The quality of generation is not superior but, it can be improved with lots of fine-tuning with some tweaks.
Conclusion#
Finally, I would like to conclude by stating that we are on the verge of witnessing a tremendous shift in the digital content we consume online. From advertisements to cinema experiences in movie theaters, everything will incorporate some form of these Generative AI applications featuring unreal elements in their content. It is essential for us get acquainted with these technologies as they are will create new opportunities across various sectors.
While this technology streamlines certain aspects of content creation in digital media, it also opens the door for individuals with malicious intent to utilize it negatively. The prevalence of DeepFakes is on the rise, fraudsters can easily clone voices for deceptive purposes, and verifying the authenticity of simple news content can become even more challenging.
Software/Tools#
Diffusion GUI#
- SD Web UI: Used in this tutorial
- ComfyUI: Advanced diffusion GUI tool which takes graphical node based approach to design simple to complex workflows.
Web UI Extensions#
- AnimateDiff: Enable motion model based animation support in webui.
- ControlNet: Let's you to copy human pose, expression, colors, contents, etc of some reference image to your target image.
- TemporalKit: Temporal Kit is a helper extension for using EbSynth, an app that lets you style videos frame by frame.