Small Language Models (SLMs) is all you need
Harnessing the full potential of Language Models! Say Hello to Small Language Models!
 Credit: BEEspoke Data/smol-llama
Credit: BEEspoke Data/smol-llama Large Language Models (LLMs) dominated the market in 2023, and my prediction for this year is an increasing prevalence of even larger models with multi-modal capacities. These advanced models can seamlessly process audio, comprehend text, and generate data in various formats such as text, audio, or video. While large models excel in supporting a wide range of tasks and capabilities, they come at a cost – both in terms of CPU/GPU usage and your budget. Additionally, the expenses related to server capabilities, including hosting, power, and maintenance, are expected to rise in the coming years.
Reasons Why Large Models Might be Overkill#
Tailored Solutions for Specific Needs: While having the ability to reason extensively is beneficial, for most users developing applications, the focus is often on specific business or task-oriented use cases such as summarization, creative content writing, or translation. Not every scenario requires the complexity of a large network.
Fine-Tuning for Business: Traditional wisdom suggests that over 80% of the time, business use-cases requires fine-tuned models. Utilizing concepts like RAG to provide in-context information improves the quality of outputs, but a fine-tuned version tailored to the specific problem at hand consistently outperforms generic large models.
Cost Considerations: Operating on the cloud incurs expenses. Opting for smaller models and running them on-premises or at edge locations can significantly cut costs, making efficient use of resources without compromising performance and security.
Ease of Maintenance: Managing AI is akin to tinkering with an unknown force, leading to positive outcomes but also numerous failed experiments. Despite the mathematical reasoning behind AI, LLMs involve passing inputs through deep layers of neural networks, posing challenges in model explainability. As we move forward, breakthroughs in understanding these intricate black boxes are crucial to prevent tech saturation.
Enhanced Portability: Building smaller models with minimal computational demands enables easy portability to diverse hardware devices, including phones, smartwatches, tablets, Raspberry Pi, and more. Empowering IoT devices with intelligent models tailored to specific use cases becomes seamless and accessible.
Streamlining Models with Quantization Techniques#
The concept of quantization has been in play since the introduction of the ONNX format. This technique optimizes and reduces model weights, effectively scaling down the overall model size.
The advent of Large Language Models (LLMs) brought forth a variety of model formats and optimization techniques aimed at efficiently reducing model size. The goal is to maintain model perplexity—assessing how well a probability model predicts a sample—while significantly reducing overall dimensions.
Activation Aware Quantization (AWQ): AWQ safeguards critical weights by optimizing per-channel scaling based on activation rather than weights. Demonstrating superior performance on language modeling and QA benchmarks, AWQ excels in quantization, making it an ideal solution for compressing models to 3/4 bits, ensuring efficient deployment in various applications.
Floating Point/Arithmetic Quantization (FP): Typically, models are built using high-precision FP32 datatypes. However, the aim of this quantization is to shift the model from FP32 to lower datatypes (FP16, int8, int4), representing a normalized version of the original values. Although this trade-off leads to reduced precision, affecting the quality of the model output, it facilitates a substantial reduction in size.
Post Training Quantization for GPT (GPTQ): This is a one-shot weight quantization method designed for Generative Pre-trained Transformer (GPT) models. GPTQ can quantize models with 175 billion parameters to 3 or 4 bits per weight, resulting in negligible accuracy degradation. In comparison to previous methods, it offers significant compression gains. This technique enables the execution of large models on a single GPU for generative inference, leading to notable inference speedups over FP16. Read more: here.
GGML/GGUF: GGML is a machine learning library written in C, created by Georgi Gerganov. The library provides foundational elements for creating tensor based neural networks, but also a unique binary format to distribute LLMs. GGML served as the initial format of this binary format and it recently translated to GGUF as to introduces broader range of parameters, custom tokenizer features, etc making it future proof. The library offers various levels of quantization, where it combines tensors and reduces down the scale (floating point precision) of some group thus yielding to reduction in model size. Read more: here
@oobabooga (Founder of text-generation-webui) has published a detailed report on the comparison of different quantization techniques.

As you can see there is a significant reduction in memory as the model loses its perplexity.
LLAMA.CPP#
Originally, this project emerged to execute LLAMA series models on CPU devices by compiling them into machine code specific to those devices. Over time, the project has expanded significantly to accommodate various model architectures, enabling execution on diverse hardware devices such as MAC, ARM, CUDA, and more. It is constructed with a focus on optimizing performance. Notably, the project has introduced a new format, GGML/GGUF, for storing and sharing the original model weights in a compressed format. Visualize it as a unified binary file encapsulating essential elements like tokenizers, models, configurations, vocabularies, etc., required for running your model—all neatly packed into a single format. GGUF succeeds GGML and extends its support to non-LLAMA models, incorporating token-extension capabilities. I highly recommend exploring this development further.
Project: link
What are my options for small language models?#
TinyLlama (1.1B)#
- Same architecture and tokenizer as Llama 2 but parameters scaled down.
- Trained on 3 Trillion Tokens.
- Supports sequence lengths of 2048.
- Github
TinyMistral (248M)#
- Based on Mistral architecture.
- The base model may not be suitable for conversation, but there are variants like the "Instruct" version designed to support chat applications.
- Supports sequence lengths of up to 32k.
- Github
Smol Llama (101M)#
- A smaller version of the Llama model trained from scratch on different datasets.
- Github
LLM.js#
LLM.js is my side hobby project, designed to facilitate the execution of Language Models in various inference formats on the web. Inspired by transformers.js, which aims to bring the transformer ecosystem into browsers, LLM.js is more specific, focusing on text-generation use cases with different language model formats and architectures.
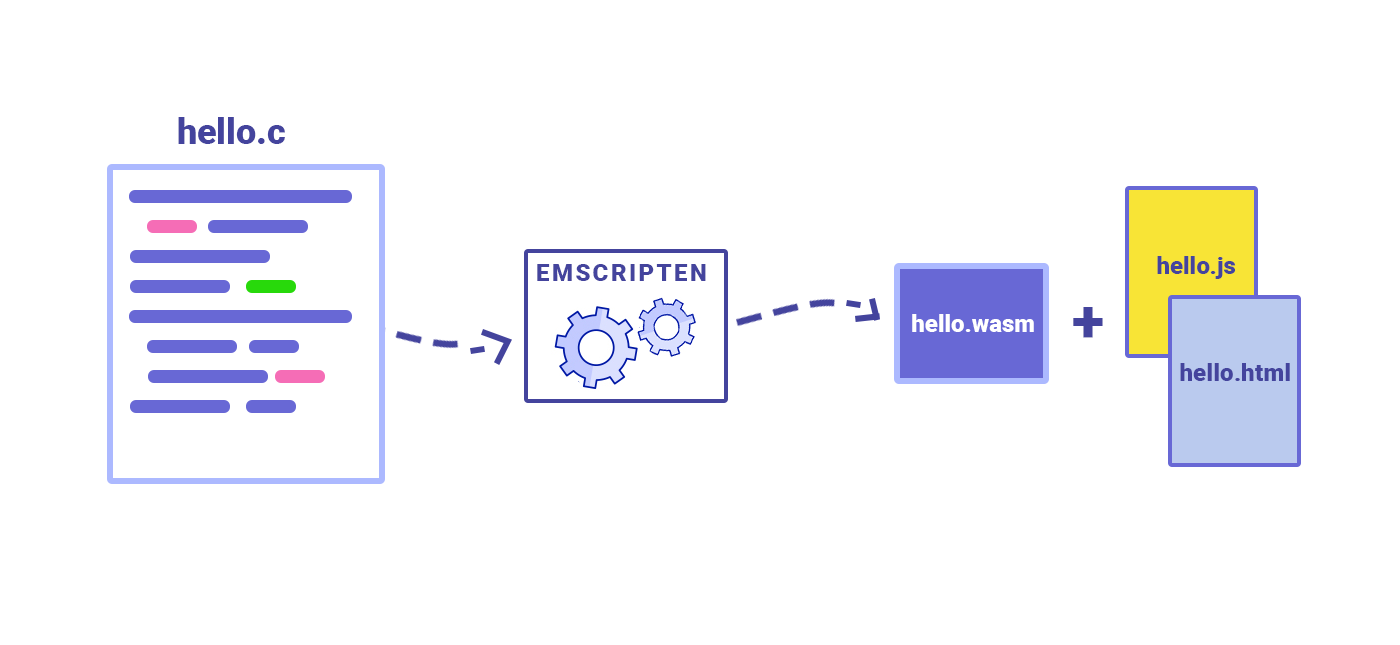
The project owes its existence to the collaborative efforts of the community, particularly on projects like LLAMA.CPP, llama.c, and Emscripten. Emscripten enables the compilation of projects into the WebAssembly (WASM) format, allowing them to be executed in a web browser's WebAssembly engine.
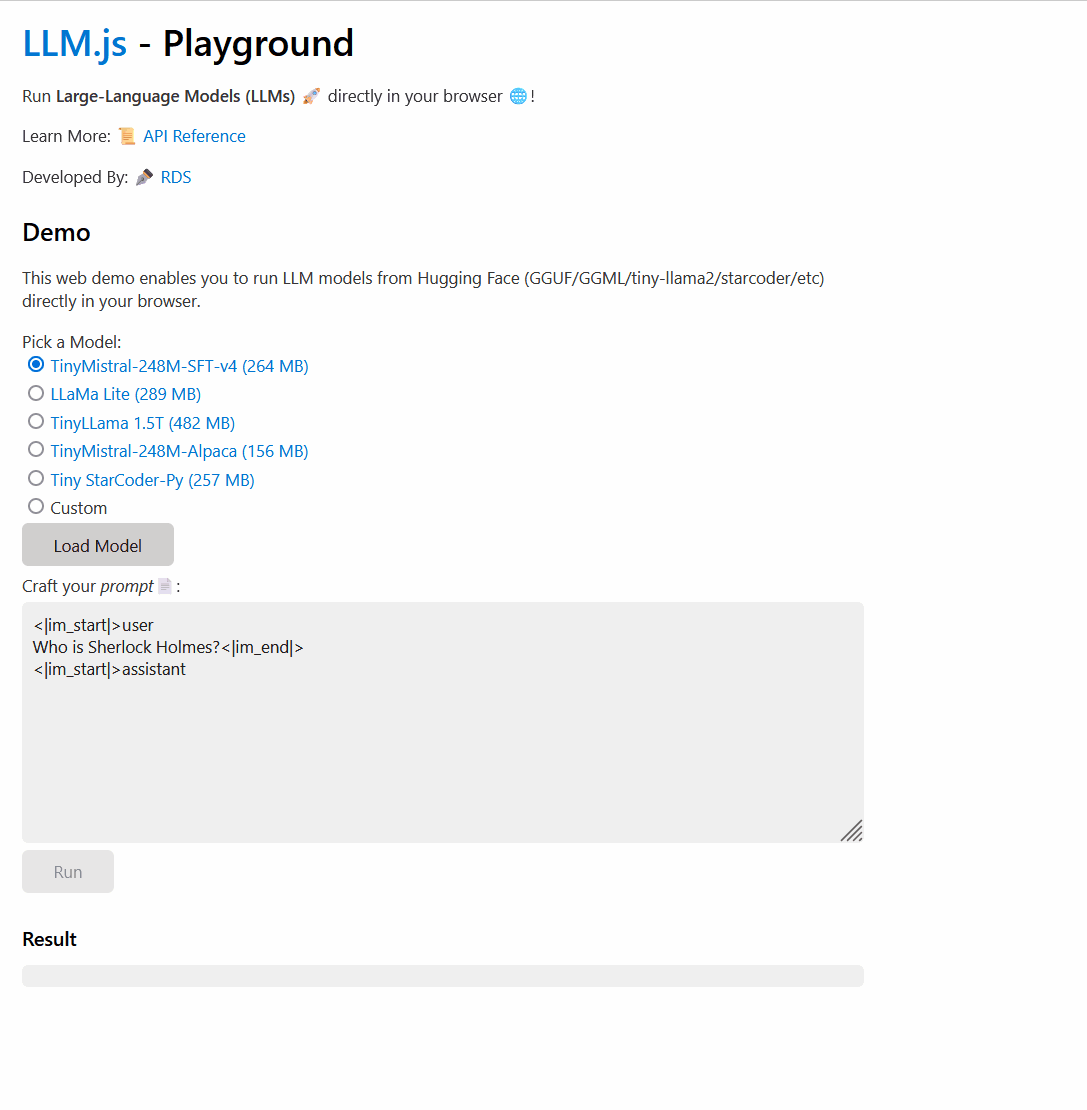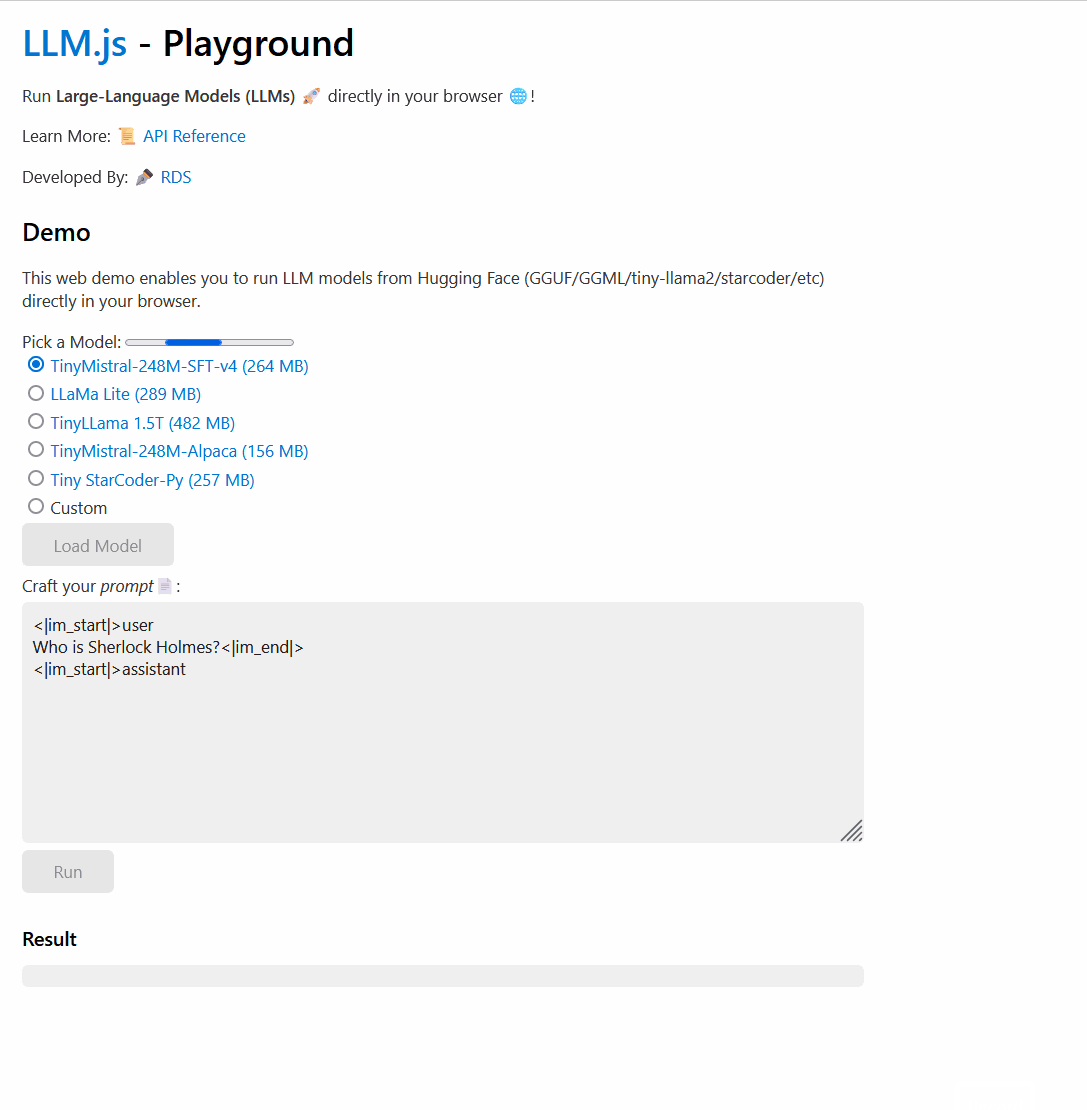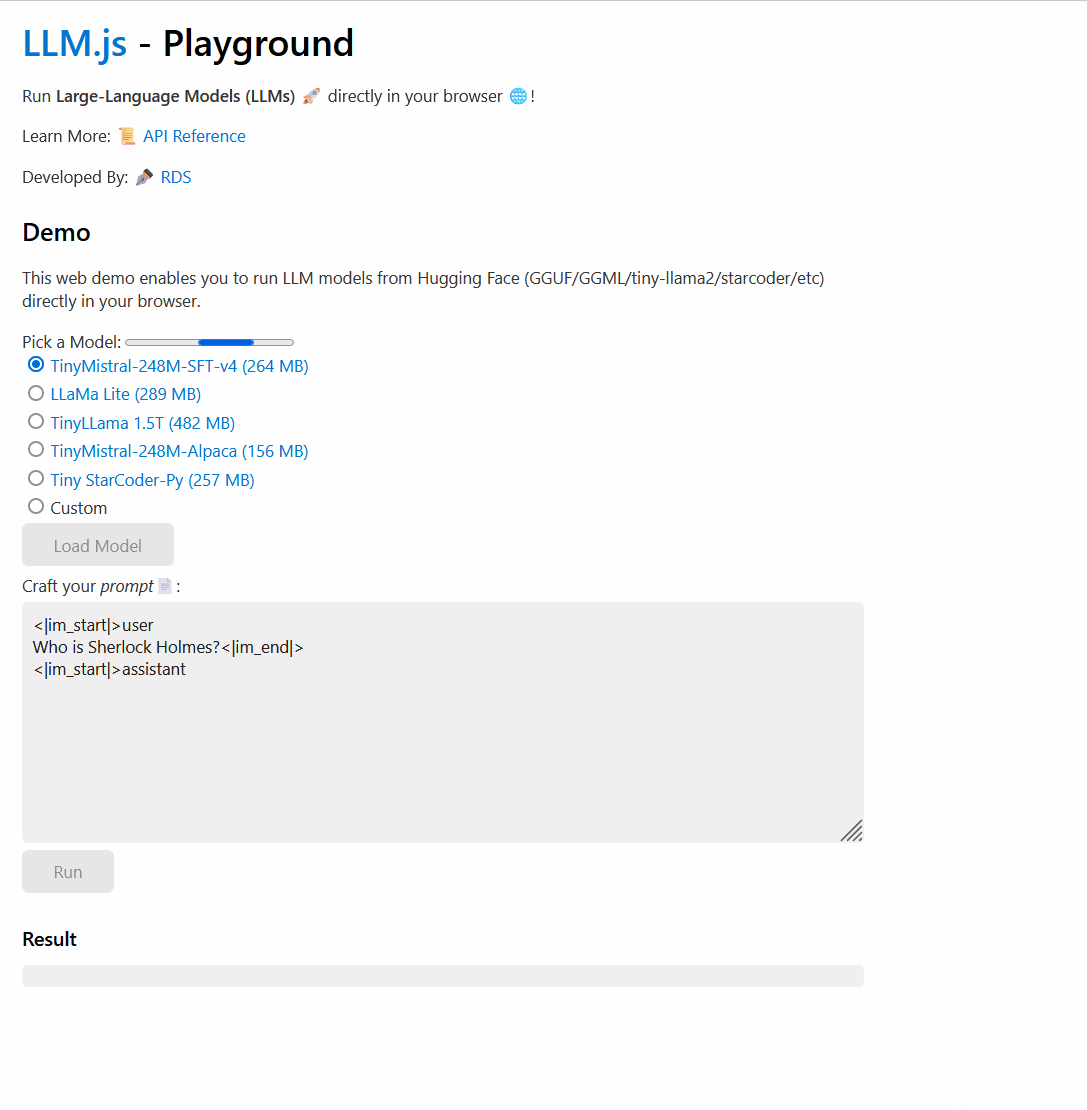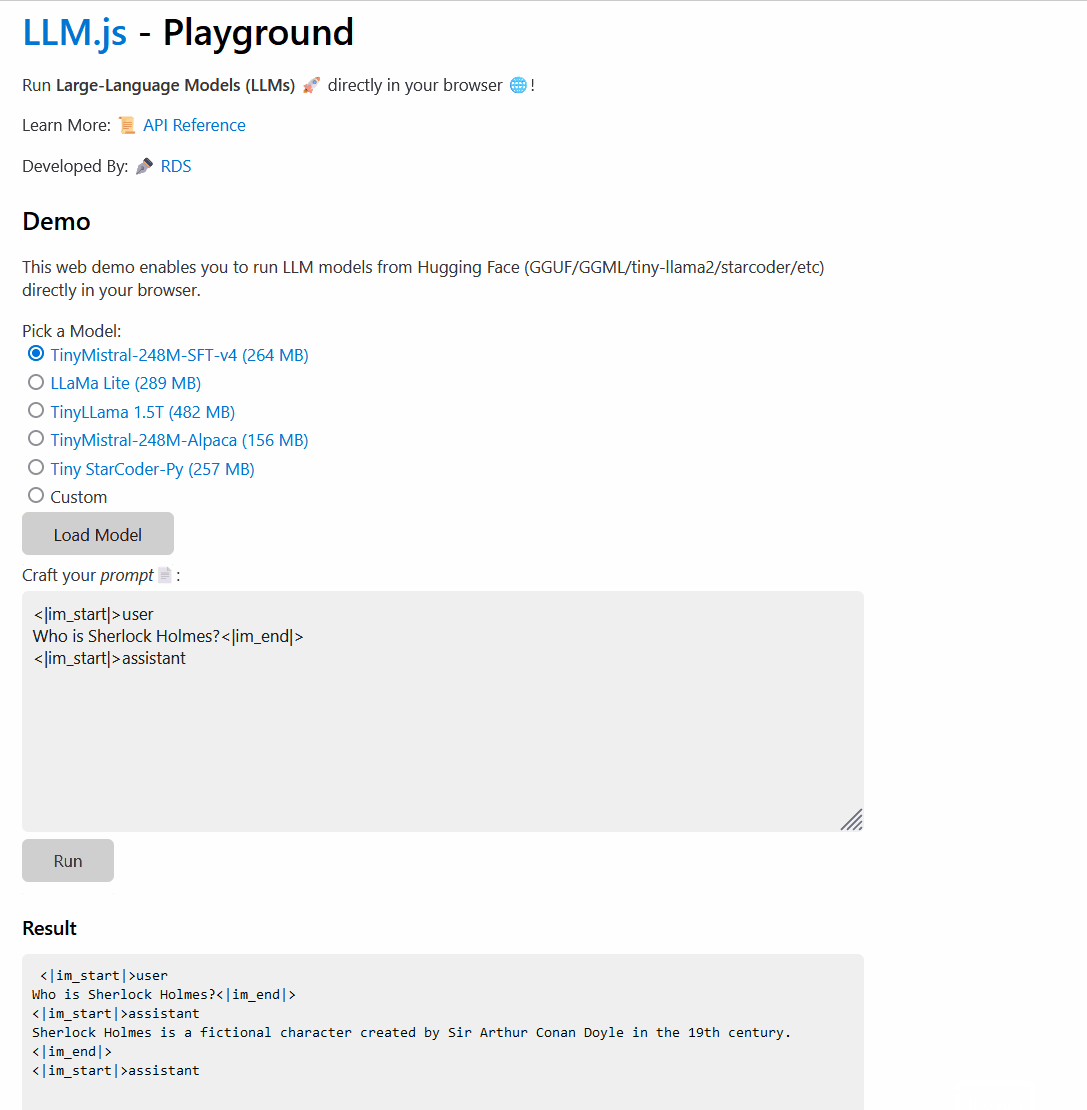
LLM.js - Playground#
Playground simplifies the process of testing various Language Models (LM) directly in your web browser. No additional dependencies are required, apart from a standard web browser (which should support WASM, a feature most modern browsers include).
The playground allows you to effortlessly fetch supported models from Hugging Face and execute them in your browser. You can customize the initial prompt and engage in text generation. While currently, direct modification of model parameters is not supported, this functionality is actively under development for the playground UI.
Playground Demo: link
Source Code: Playground